Structure Learning in Bayesian Networks¶
In this notebook, we show a few examples of Causal Discovery or Structure Learning in pgmpy. pgmpy currently has the following algorithm for causal discovery:
PC: Has
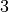 variants original, stable, and parallel. PC is a constraint-based algorithm that utilizes Conditional Independence tests to construct the model.
variants original, stable, and parallel. PC is a constraint-based algorithm that utilizes Conditional Independence tests to construct the model.Hill-Climb Search: Hill-Climb Search is a greedy optimization-based algorithm that makes iterative local changes to the model structure such that it improves the overall score of the model.
Greedy Equivalence Search (GES): Another score-based method that makes greedy modifications to the model to improve its score iteratively.
ExpertInLoop: An iterative algorithm that combines Conditional Independence testing with expert knowledge. The user or an LLM can act as the expert.
Exhaustive Search: Exhaustive search iterates over all possible network structures on the given variables to find the most optimal one. As it tries to enumerate all possible network structures, it is intractable when the number of variables in the data is large.
The following Conditional Independence Tests are available to use with PC algorithm. 1. Discrete Data: When all variables are discrete/categorical. 1. Chi-square test: ci_test="chi_square" 2. G-squared: ci_test="g_sq" 3. Log-likelihood: Is equivalent to G-squared test. ci_test="log_likelihood 2. Continuous Data: When all variables are continuous/numerical. 1. Partial Correlation: ci_test="pearsonr" 3. Mixed Data: When there is a mix of categorical and
continuous variables. 1. Pillai: ci_test="pillai"
For Hill-Climb, Exhausitive Search, and GES the following scoring methods can be used: 1. Discrete Data: When all variables are discrete/categorical. 1. BIC Score: scoring_method="bic-d" 2. AIC Score: scoring_method="aic-d" 3. K2 Score: scoring_method="k2" 4. BDeU Score: scoring_method="bdeu" 5. BDs Score: scoring_method="bds" 2. Continuous Data: When all variables are continuous/numerical. 1. Log-Likelihood: scoring_method="ll-g" 2.
AIC: scoring_method="aic-g" 3. BIC: scoring_method="bic-g" 3. Mixed Data: When there is a mix of discrete and continuous variables. 1. AIC: scoring_method="aic-cg" 2. BIC: scoring_method="bic-cg"
0. Simulate some sample datasets¶
[1]:
from itertools import combinations
import networkx as nx
import numpy as np
from sklearn.metrics import f1_score
from pgmpy.estimators import PC, HillClimbSearch, GES
from pgmpy.utils import get_example_model
from pgmpy.metrics import SHD
[2]:
# Discrete variable dataset
alarm_model = get_example_model("alarm")
alarm_samples = alarm_model.simulate(int(1e3))
alarm_samples.head()
# Continuous variable dataset
ecoli_model = get_example_model("ecoli70")
ecoli_samples = ecoli_model.simulate(int(1e3))
ecoli_samples.head()
WARNING:pgmpy:Probability values don't exactly sum to 1. Differ by: -2.220446049250313e-16. Adjusting values.
[2]:
| b1191 | cspG | eutG | fixC | cspA | yecO | yedE | sucA | cchB | yceP | ... | dnaK | folK | ycgX | lacZ | nuoM | dnaG | b1583 | mopB | yaeM | ftsJ | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1.060641 | 2.044477 | 0.341216 | 1.448399 | -0.351716 | 2.189750 | -1.689554 | -0.228456 | 2.871002 | -0.433597 | ... | 1.522817 | 1.645983 | 1.595502 | 2.465247 | -0.532987 | 1.126289 | -0.302589 | 0.773483 | 3.884857 | 0.729557 |
| 1 | 0.632151 | 0.964321 | 0.830229 | 0.696598 | 0.639204 | 0.058108 | -0.736189 | 0.712095 | 1.467498 | 0.320727 | ... | 1.222602 | 1.790727 | 1.763590 | 2.945772 | -2.532464 | 1.460699 | 2.732595 | 0.097982 | 2.566064 | 0.652853 |
| 2 | 0.585766 | 2.862437 | 0.922291 | 0.370000 | 0.723932 | 2.487161 | -1.916624 | -0.300359 | 2.050980 | -0.064301 | ... | 0.599305 | 1.302091 | 0.509717 | 3.090268 | -1.745613 | 0.168043 | 0.851346 | -0.640472 | 5.800712 | 0.031888 |
| 3 | 1.802866 | 2.277038 | 0.608559 | 2.180283 | 0.116453 | 2.539035 | -1.656839 | -1.420540 | 2.605192 | -0.160302 | ... | 2.015663 | 2.823588 | 2.101625 | 3.521299 | -1.212391 | 1.485369 | 2.449296 | 2.032116 | 3.888917 | 3.036650 |
| 4 | 1.868548 | 2.480999 | 1.079364 | 2.413862 | 0.961743 | 2.280195 | -1.740610 | -0.472692 | 3.338063 | -0.509144 | ... | 1.142139 | 1.251832 | -0.145789 | 2.057217 | -2.862230 | -0.089721 | 1.020832 | 0.040589 | 4.925848 | 0.575977 |
5 rows × 46 columns
[3]:
# Function to evaluate the learned model structures.
def get_f1_score(estimated_model, true_model):
nodes = estimated_model.nodes()
est_adj = nx.to_numpy_array(
estimated_model.to_undirected(), nodelist=nodes, weight=None
)
true_adj = nx.to_numpy_array(
true_model.to_undirected(), nodelist=nodes, weight=None
)
f1 = f1_score(np.ravel(true_adj), np.ravel(est_adj))
print("F1-score for the model skeleton: ", f1)
1. PC algorithm¶
[4]:
# Learning the discrete variable alarm model back
est = PC(data=alarm_samples)
estimated_model = est.estimate(ci_test='chi_square', variant="stable", max_cond_vars=4, return_type='dag')
get_f1_score(estimated_model, alarm_model)
INFO:pgmpy: Datatype (N=numerical, C=Categorical Unordered, O=Categorical Ordered) inferred from data:
{'INTUBATION': 'C', 'ANAPHYLAXIS': 'C', 'VENTLUNG': 'C', 'HISTORY': 'C', 'LVEDVOLUME': 'C', 'VENTMACH': 'C', 'TPR': 'C', 'MINVOL': 'C', 'VENTTUBE': 'C', 'HRBP': 'C', 'BP': 'C', 'PAP': 'C', 'PULMEMBOLUS': 'C', 'DISCONNECT': 'C', 'ERRLOWOUTPUT': 'C', 'HYPOVOLEMIA': 'C', 'CVP': 'C', 'HREKG': 'C', 'CO': 'C', 'PRESS': 'C', 'HRSAT': 'C', 'CATECHOL': 'C', 'EXPCO2': 'C', 'PVSAT': 'C', 'ARTCO2': 'C', 'LVFAILURE': 'C', 'KINKEDTUBE': 'C', 'VENTALV': 'C', 'FIO2': 'C', 'SHUNT': 'C', 'PCWP': 'C', 'SAO2': 'C', 'HR': 'C', 'MINVOLSET': 'C', 'STROKEVOLUME': 'C', 'INSUFFANESTH': 'C', 'ERRCAUTER': 'C'}
INFO:pgmpy:Reached maximum number of allowed conditional variables. Exiting
F1-score for the model skeleton: 0.825
[5]:
# Learning the continuous variable ecoli model back
est = PC(data=ecoli_samples)
estimated_model = est.estimate(ci_test='pearsonr', variant="orig", max_cond_vars=4, return_type='dag')
get_f1_score(estimated_model, ecoli_model)
INFO:pgmpy: Datatype (N=numerical, C=Categorical Unordered, O=Categorical Ordered) inferred from data:
{'b1191': 'N', 'cspG': 'N', 'eutG': 'N', 'fixC': 'N', 'cspA': 'N', 'yecO': 'N', 'yedE': 'N', 'sucA': 'N', 'cchB': 'N', 'yceP': 'N', 'ygbD': 'N', 'yjbO': 'N', 'yfiA': 'N', 'lpdA': 'N', 'pspB': 'N', 'atpG': 'N', 'dnaJ': 'N', 'flgD': 'N', 'gltA': 'N', 'sucD': 'N', 'tnaA': 'N', 'ygcE': 'N', 'yhdM': 'N', 'ibpB': 'N', 'yfaD': 'N', 'hupB': 'N', 'pspA': 'N', 'asnA': 'N', 'atpD': 'N', 'nmpC': 'N', 'icdA': 'N', 'lacA': 'N', 'yheI': 'N', 'aceB': 'N', 'lacY': 'N', 'b1963': 'N', 'dnaK': 'N', 'folK': 'N', 'ycgX': 'N', 'lacZ': 'N', 'nuoM': 'N', 'dnaG': 'N', 'b1583': 'N', 'mopB': 'N', 'yaeM': 'N', 'ftsJ': 'N'}
INFO:pgmpy:Reached maximum number of allowed conditional variables. Exiting
F1-score for the model skeleton: 0.640625
2. Hill-Climb Search Algorithm¶
[6]:
# Learning the discrete variable alarm model back
est = HillClimbSearch(data=alarm_samples)
estimated_model = est.estimate(scoring_method="k2", max_indegree=4, max_iter=int(1e4))
get_f1_score(estimated_model, alarm_model)
INFO:pgmpy: Datatype (N=numerical, C=Categorical Unordered, O=Categorical Ordered) inferred from data:
{'INTUBATION': 'C', 'ANAPHYLAXIS': 'C', 'VENTLUNG': 'C', 'HISTORY': 'C', 'LVEDVOLUME': 'C', 'VENTMACH': 'C', 'TPR': 'C', 'MINVOL': 'C', 'VENTTUBE': 'C', 'HRBP': 'C', 'BP': 'C', 'PAP': 'C', 'PULMEMBOLUS': 'C', 'DISCONNECT': 'C', 'ERRLOWOUTPUT': 'C', 'HYPOVOLEMIA': 'C', 'CVP': 'C', 'HREKG': 'C', 'CO': 'C', 'PRESS': 'C', 'HRSAT': 'C', 'CATECHOL': 'C', 'EXPCO2': 'C', 'PVSAT': 'C', 'ARTCO2': 'C', 'LVFAILURE': 'C', 'KINKEDTUBE': 'C', 'VENTALV': 'C', 'FIO2': 'C', 'SHUNT': 'C', 'PCWP': 'C', 'SAO2': 'C', 'HR': 'C', 'MINVOLSET': 'C', 'STROKEVOLUME': 'C', 'INSUFFANESTH': 'C', 'ERRCAUTER': 'C'}
INFO:pgmpy: Datatype (N=numerical, C=Categorical Unordered, O=Categorical Ordered) inferred from data:
{'INTUBATION': 'C', 'ANAPHYLAXIS': 'C', 'VENTLUNG': 'C', 'HISTORY': 'C', 'LVEDVOLUME': 'C', 'VENTMACH': 'C', 'TPR': 'C', 'MINVOL': 'C', 'VENTTUBE': 'C', 'HRBP': 'C', 'BP': 'C', 'PAP': 'C', 'PULMEMBOLUS': 'C', 'DISCONNECT': 'C', 'ERRLOWOUTPUT': 'C', 'HYPOVOLEMIA': 'C', 'CVP': 'C', 'HREKG': 'C', 'CO': 'C', 'PRESS': 'C', 'HRSAT': 'C', 'CATECHOL': 'C', 'EXPCO2': 'C', 'PVSAT': 'C', 'ARTCO2': 'C', 'LVFAILURE': 'C', 'KINKEDTUBE': 'C', 'VENTALV': 'C', 'FIO2': 'C', 'SHUNT': 'C', 'PCWP': 'C', 'SAO2': 'C', 'HR': 'C', 'MINVOLSET': 'C', 'STROKEVOLUME': 'C', 'INSUFFANESTH': 'C', 'ERRCAUTER': 'C'}
INFO:pgmpy: Datatype (N=numerical, C=Categorical Unordered, O=Categorical Ordered) inferred from data:
{'INTUBATION': 'C', 'ANAPHYLAXIS': 'C', 'VENTLUNG': 'C', 'HISTORY': 'C', 'LVEDVOLUME': 'C', 'VENTMACH': 'C', 'TPR': 'C', 'MINVOL': 'C', 'VENTTUBE': 'C', 'HRBP': 'C', 'BP': 'C', 'PAP': 'C', 'PULMEMBOLUS': 'C', 'DISCONNECT': 'C', 'ERRLOWOUTPUT': 'C', 'HYPOVOLEMIA': 'C', 'CVP': 'C', 'HREKG': 'C', 'CO': 'C', 'PRESS': 'C', 'HRSAT': 'C', 'CATECHOL': 'C', 'EXPCO2': 'C', 'PVSAT': 'C', 'ARTCO2': 'C', 'LVFAILURE': 'C', 'KINKEDTUBE': 'C', 'VENTALV': 'C', 'FIO2': 'C', 'SHUNT': 'C', 'PCWP': 'C', 'SAO2': 'C', 'HR': 'C', 'MINVOLSET': 'C', 'STROKEVOLUME': 'C', 'INSUFFANESTH': 'C', 'ERRCAUTER': 'C'}
F1-score for the model skeleton: 0.7719298245614035
[7]:
# Learning the continuous variable ecoli model back
est = HillClimbSearch(data=ecoli_samples)
estimated_model = est.estimate(scoring_method="bic-g", max_indegree=4, max_iter=int(1e4))
get_f1_score(estimated_model, ecoli_model)
INFO:pgmpy: Datatype (N=numerical, C=Categorical Unordered, O=Categorical Ordered) inferred from data:
{'b1191': 'N', 'cspG': 'N', 'eutG': 'N', 'fixC': 'N', 'cspA': 'N', 'yecO': 'N', 'yedE': 'N', 'sucA': 'N', 'cchB': 'N', 'yceP': 'N', 'ygbD': 'N', 'yjbO': 'N', 'yfiA': 'N', 'lpdA': 'N', 'pspB': 'N', 'atpG': 'N', 'dnaJ': 'N', 'flgD': 'N', 'gltA': 'N', 'sucD': 'N', 'tnaA': 'N', 'ygcE': 'N', 'yhdM': 'N', 'ibpB': 'N', 'yfaD': 'N', 'hupB': 'N', 'pspA': 'N', 'asnA': 'N', 'atpD': 'N', 'nmpC': 'N', 'icdA': 'N', 'lacA': 'N', 'yheI': 'N', 'aceB': 'N', 'lacY': 'N', 'b1963': 'N', 'dnaK': 'N', 'folK': 'N', 'ycgX': 'N', 'lacZ': 'N', 'nuoM': 'N', 'dnaG': 'N', 'b1583': 'N', 'mopB': 'N', 'yaeM': 'N', 'ftsJ': 'N'}
INFO:pgmpy: Datatype (N=numerical, C=Categorical Unordered, O=Categorical Ordered) inferred from data:
{'b1191': 'N', 'cspG': 'N', 'eutG': 'N', 'fixC': 'N', 'cspA': 'N', 'yecO': 'N', 'yedE': 'N', 'sucA': 'N', 'cchB': 'N', 'yceP': 'N', 'ygbD': 'N', 'yjbO': 'N', 'yfiA': 'N', 'lpdA': 'N', 'pspB': 'N', 'atpG': 'N', 'dnaJ': 'N', 'flgD': 'N', 'gltA': 'N', 'sucD': 'N', 'tnaA': 'N', 'ygcE': 'N', 'yhdM': 'N', 'ibpB': 'N', 'yfaD': 'N', 'hupB': 'N', 'pspA': 'N', 'asnA': 'N', 'atpD': 'N', 'nmpC': 'N', 'icdA': 'N', 'lacA': 'N', 'yheI': 'N', 'aceB': 'N', 'lacY': 'N', 'b1963': 'N', 'dnaK': 'N', 'folK': 'N', 'ycgX': 'N', 'lacZ': 'N', 'nuoM': 'N', 'dnaG': 'N', 'b1583': 'N', 'mopB': 'N', 'yaeM': 'N', 'ftsJ': 'N'}
INFO:pgmpy: Datatype (N=numerical, C=Categorical Unordered, O=Categorical Ordered) inferred from data:
{'b1191': 'N', 'cspG': 'N', 'eutG': 'N', 'fixC': 'N', 'cspA': 'N', 'yecO': 'N', 'yedE': 'N', 'sucA': 'N', 'cchB': 'N', 'yceP': 'N', 'ygbD': 'N', 'yjbO': 'N', 'yfiA': 'N', 'lpdA': 'N', 'pspB': 'N', 'atpG': 'N', 'dnaJ': 'N', 'flgD': 'N', 'gltA': 'N', 'sucD': 'N', 'tnaA': 'N', 'ygcE': 'N', 'yhdM': 'N', 'ibpB': 'N', 'yfaD': 'N', 'hupB': 'N', 'pspA': 'N', 'asnA': 'N', 'atpD': 'N', 'nmpC': 'N', 'icdA': 'N', 'lacA': 'N', 'yheI': 'N', 'aceB': 'N', 'lacY': 'N', 'b1963': 'N', 'dnaK': 'N', 'folK': 'N', 'ycgX': 'N', 'lacZ': 'N', 'nuoM': 'N', 'dnaG': 'N', 'b1583': 'N', 'mopB': 'N', 'yaeM': 'N', 'ftsJ': 'N'}
F1-score for the model skeleton: 0.7692307692307693
3. GES algorithm¶
[9]:
# Learning the discrete variable alarm model back
est = GES(data=alarm_samples)
estimated_model = est.estimate(scoring_method="bic-d")
get_f1_score(estimated_model, alarm_model)
INFO:pgmpy: Datatype (N=numerical, C=Categorical Unordered, O=Categorical Ordered) inferred from data:
{'INTUBATION': 'C', 'ANAPHYLAXIS': 'C', 'VENTLUNG': 'C', 'HISTORY': 'C', 'LVEDVOLUME': 'C', 'VENTMACH': 'C', 'TPR': 'C', 'MINVOL': 'C', 'VENTTUBE': 'C', 'HRBP': 'C', 'BP': 'C', 'PAP': 'C', 'PULMEMBOLUS': 'C', 'DISCONNECT': 'C', 'ERRLOWOUTPUT': 'C', 'HYPOVOLEMIA': 'C', 'CVP': 'C', 'HREKG': 'C', 'CO': 'C', 'PRESS': 'C', 'HRSAT': 'C', 'CATECHOL': 'C', 'EXPCO2': 'C', 'PVSAT': 'C', 'ARTCO2': 'C', 'LVFAILURE': 'C', 'KINKEDTUBE': 'C', 'VENTALV': 'C', 'FIO2': 'C', 'SHUNT': 'C', 'PCWP': 'C', 'SAO2': 'C', 'HR': 'C', 'MINVOLSET': 'C', 'STROKEVOLUME': 'C', 'INSUFFANESTH': 'C', 'ERRCAUTER': 'C'}
INFO:pgmpy: Datatype (N=numerical, C=Categorical Unordered, O=Categorical Ordered) inferred from data:
{'INTUBATION': 'C', 'ANAPHYLAXIS': 'C', 'VENTLUNG': 'C', 'HISTORY': 'C', 'LVEDVOLUME': 'C', 'VENTMACH': 'C', 'TPR': 'C', 'MINVOL': 'C', 'VENTTUBE': 'C', 'HRBP': 'C', 'BP': 'C', 'PAP': 'C', 'PULMEMBOLUS': 'C', 'DISCONNECT': 'C', 'ERRLOWOUTPUT': 'C', 'HYPOVOLEMIA': 'C', 'CVP': 'C', 'HREKG': 'C', 'CO': 'C', 'PRESS': 'C', 'HRSAT': 'C', 'CATECHOL': 'C', 'EXPCO2': 'C', 'PVSAT': 'C', 'ARTCO2': 'C', 'LVFAILURE': 'C', 'KINKEDTUBE': 'C', 'VENTALV': 'C', 'FIO2': 'C', 'SHUNT': 'C', 'PCWP': 'C', 'SAO2': 'C', 'HR': 'C', 'MINVOLSET': 'C', 'STROKEVOLUME': 'C', 'INSUFFANESTH': 'C', 'ERRCAUTER': 'C'}
INFO:pgmpy: Datatype (N=numerical, C=Categorical Unordered, O=Categorical Ordered) inferred from data:
{'INTUBATION': 'C', 'ANAPHYLAXIS': 'C', 'VENTLUNG': 'C', 'HISTORY': 'C', 'LVEDVOLUME': 'C', 'VENTMACH': 'C', 'TPR': 'C', 'MINVOL': 'C', 'VENTTUBE': 'C', 'HRBP': 'C', 'BP': 'C', 'PAP': 'C', 'PULMEMBOLUS': 'C', 'DISCONNECT': 'C', 'ERRLOWOUTPUT': 'C', 'HYPOVOLEMIA': 'C', 'CVP': 'C', 'HREKG': 'C', 'CO': 'C', 'PRESS': 'C', 'HRSAT': 'C', 'CATECHOL': 'C', 'EXPCO2': 'C', 'PVSAT': 'C', 'ARTCO2': 'C', 'LVFAILURE': 'C', 'KINKEDTUBE': 'C', 'VENTALV': 'C', 'FIO2': 'C', 'SHUNT': 'C', 'PCWP': 'C', 'SAO2': 'C', 'HR': 'C', 'MINVOLSET': 'C', 'STROKEVOLUME': 'C', 'INSUFFANESTH': 'C', 'ERRCAUTER': 'C'}
F1-score for the model skeleton: 0.8444444444444444
[10]:
# Learning the continuous variable ecoli model back
est = GES(data=ecoli_samples)
estimated_model = est.estimate(scoring_method="bic-g")
get_f1_score(estimated_model, ecoli_model)
INFO:pgmpy: Datatype (N=numerical, C=Categorical Unordered, O=Categorical Ordered) inferred from data:
{'b1191': 'N', 'cspG': 'N', 'eutG': 'N', 'fixC': 'N', 'cspA': 'N', 'yecO': 'N', 'yedE': 'N', 'sucA': 'N', 'cchB': 'N', 'yceP': 'N', 'ygbD': 'N', 'yjbO': 'N', 'yfiA': 'N', 'lpdA': 'N', 'pspB': 'N', 'atpG': 'N', 'dnaJ': 'N', 'flgD': 'N', 'gltA': 'N', 'sucD': 'N', 'tnaA': 'N', 'ygcE': 'N', 'yhdM': 'N', 'ibpB': 'N', 'yfaD': 'N', 'hupB': 'N', 'pspA': 'N', 'asnA': 'N', 'atpD': 'N', 'nmpC': 'N', 'icdA': 'N', 'lacA': 'N', 'yheI': 'N', 'aceB': 'N', 'lacY': 'N', 'b1963': 'N', 'dnaK': 'N', 'folK': 'N', 'ycgX': 'N', 'lacZ': 'N', 'nuoM': 'N', 'dnaG': 'N', 'b1583': 'N', 'mopB': 'N', 'yaeM': 'N', 'ftsJ': 'N'}
INFO:pgmpy: Datatype (N=numerical, C=Categorical Unordered, O=Categorical Ordered) inferred from data:
{'b1191': 'N', 'cspG': 'N', 'eutG': 'N', 'fixC': 'N', 'cspA': 'N', 'yecO': 'N', 'yedE': 'N', 'sucA': 'N', 'cchB': 'N', 'yceP': 'N', 'ygbD': 'N', 'yjbO': 'N', 'yfiA': 'N', 'lpdA': 'N', 'pspB': 'N', 'atpG': 'N', 'dnaJ': 'N', 'flgD': 'N', 'gltA': 'N', 'sucD': 'N', 'tnaA': 'N', 'ygcE': 'N', 'yhdM': 'N', 'ibpB': 'N', 'yfaD': 'N', 'hupB': 'N', 'pspA': 'N', 'asnA': 'N', 'atpD': 'N', 'nmpC': 'N', 'icdA': 'N', 'lacA': 'N', 'yheI': 'N', 'aceB': 'N', 'lacY': 'N', 'b1963': 'N', 'dnaK': 'N', 'folK': 'N', 'ycgX': 'N', 'lacZ': 'N', 'nuoM': 'N', 'dnaG': 'N', 'b1583': 'N', 'mopB': 'N', 'yaeM': 'N', 'ftsJ': 'N'}
INFO:pgmpy: Datatype (N=numerical, C=Categorical Unordered, O=Categorical Ordered) inferred from data:
{'b1191': 'N', 'cspG': 'N', 'eutG': 'N', 'fixC': 'N', 'cspA': 'N', 'yecO': 'N', 'yedE': 'N', 'sucA': 'N', 'cchB': 'N', 'yceP': 'N', 'ygbD': 'N', 'yjbO': 'N', 'yfiA': 'N', 'lpdA': 'N', 'pspB': 'N', 'atpG': 'N', 'dnaJ': 'N', 'flgD': 'N', 'gltA': 'N', 'sucD': 'N', 'tnaA': 'N', 'ygcE': 'N', 'yhdM': 'N', 'ibpB': 'N', 'yfaD': 'N', 'hupB': 'N', 'pspA': 'N', 'asnA': 'N', 'atpD': 'N', 'nmpC': 'N', 'icdA': 'N', 'lacA': 'N', 'yheI': 'N', 'aceB': 'N', 'lacY': 'N', 'b1963': 'N', 'dnaK': 'N', 'folK': 'N', 'ycgX': 'N', 'lacZ': 'N', 'nuoM': 'N', 'dnaG': 'N', 'b1583': 'N', 'mopB': 'N', 'yaeM': 'N', 'ftsJ': 'N'}
F1-score for the model skeleton: 0.8461538461538461
4. Expert In Loop Algorithm¶
Please refer to the following blogpost for more details: https://medium.com/gopenai/llms-for-causal-discovery-745e2cba0b59