Learning Bayesian Networks from Data¶
Previous notebooks showed how Bayesian networks economically encode a probability distribution over a set of variables, and how they can be used e.g. to predict variable states, or to generate new samples from the joint distribution. This section will be about obtaining a Bayesian network, given a set of sample data. Learning a Bayesian network can be split into two problems:
Parameter learning: Given a set of data samples and a DAG that captures the dependencies between the variables, estimate the (conditional) probability distributions of the individual variables.
Structure learning: Given a set of data samples, estimate a DAG that captures the dependencies between the variables.
This notebook aims to illustrate how parameter learning and structure learning can be done with pgmpy. Currently, the library supports: - Parameter learning for discrete nodes: - Maximum Likelihood Estimation - Bayesian Estimation - Structure learning for discrete, fully observed networks: - Score-based structure estimation (BIC/BDeu/K2 score; exhaustive search, hill climb/tabu search) - Constraint-based structure estimation (PC) - Hybrid structure estimation (MMHC)
Parameter Learning¶
Suppose we have the following data:
[1]:
import pandas as pd
data = pd.DataFrame(data={'fruit': ["banana", "apple", "banana", "apple", "banana","apple", "banana",
"apple", "apple", "apple", "banana", "banana", "apple", "banana",],
'tasty': ["yes", "no", "yes", "yes", "yes", "yes", "yes",
"yes", "yes", "yes", "yes", "no", "no", "no"],
'size': ["large", "large", "large", "small", "large", "large", "large",
"small", "large", "large", "large", "large", "small", "small"]})
print(data)
fruit tasty size
0 banana yes large
1 apple no large
2 banana yes large
3 apple yes small
4 banana yes large
5 apple yes large
6 banana yes large
7 apple yes small
8 apple yes large
9 apple yes large
10 banana yes large
11 banana no large
12 apple no small
13 banana no small
We know that the variables relate as follows:
[2]:
from pgmpy.models import BayesianModel
model = BayesianModel([('fruit', 'tasty'), ('size', 'tasty')]) # fruit -> tasty <- size
/home/ankur/pgmpy_notebook/notebooks/pgmpy/models/BayesianModel.py:8: FutureWarning: BayesianModel has been renamed to BayesianNetwork. Please use BayesianNetwork class, BayesianModel will be removed in future.
warnings.warn(
Parameter learning is the task to estimate the values of the conditional probability distributions (CPDs), for the variables fruit, size, and tasty.
State counts¶
To make sense of the given data, we can start by counting how often each state of the variable occurs. If the variable is dependent on parents, the counts are done conditionally on the parents states, i.e. for seperately for each parent configuration:
[3]:
from pgmpy.estimators import ParameterEstimator
pe = ParameterEstimator(model, data)
print("\n", pe.state_counts('fruit')) # unconditional
print("\n", pe.state_counts('tasty')) # conditional on fruit and size
fruit
apple 7
banana 7
fruit apple banana
size large small large small
tasty
no 1.0 1.0 1.0 1.0
yes 3.0 2.0 5.0 0.0
We can see, for example, that as many apples as bananas were observed and that 5 large bananas were tasty, while only 1 was not.
Maximum Likelihood Estimation¶
A natural estimate for the CPDs is to simply use the relative frequencies, with which the variable states have occured. We observed 7 apples among a total of 14 fruits, so we might guess that about 50% of fruits are apples.
This approach is Maximum Likelihood Estimation (MLE). According to MLE, we should fill the CPDs in such a way, that 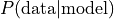 is maximal. This is achieved when using the relative frequencies. See [1], section 17.1 for an introduction to ML parameter estimation. pgmpy supports MLE as follows:
is maximal. This is achieved when using the relative frequencies. See [1], section 17.1 for an introduction to ML parameter estimation. pgmpy supports MLE as follows:
[4]:
from pgmpy.estimators import MaximumLikelihoodEstimator
mle = MaximumLikelihoodEstimator(model, data)
print(mle.estimate_cpd('fruit')) # unconditional
print(mle.estimate_cpd('tasty')) # conditional
+---------------+-----+
| fruit(apple) | 0.5 |
+---------------+-----+
| fruit(banana) | 0.5 |
+---------------+-----+
+------------+--------------+-----+---------------+
| fruit | fruit(apple) | ... | fruit(banana) |
+------------+--------------+-----+---------------+
| size | size(large) | ... | size(small) |
+------------+--------------+-----+---------------+
| tasty(no) | 0.25 | ... | 1.0 |
+------------+--------------+-----+---------------+
| tasty(yes) | 0.75 | ... | 0.0 |
+------------+--------------+-----+---------------+
mle.estimate_cpd(variable) computes the state counts and divides each cell by the (conditional) sample size. The mle.get_parameters()-method returns a list of CPDs for all variable of the model.
The built-in fit()-method of BayesianModel provides more convenient access to parameter estimators:
[5]:
# Calibrate all CPDs of `model` using MLE:
model.fit(data, estimator=MaximumLikelihoodEstimator)
While very straightforward, the ML estimator has the problem of overfitting to the data. In above CPD, the probability of a large banana being tasty is estimated at 0.833, because 5 out of 6 observed large bananas were tasty. Fine. But note that the probability of a small banana being tasty is estimated at 0.0, because we observed only one small banana and it happened to be not tasty. But that should hardly make us certain that small bananas aren’t tasty! We simply do not have
enough observations to rely on the observed frequencies. If the observed data is not representative for the underlying distribution, ML estimations will be extremly far off.
When estimating parameters for Bayesian networks, lack of data is a frequent problem. Even if the total sample size is very large, the fact that state counts are done conditionally for each parents configuration causes immense fragmentation. If a variable has 3 parents that can each take 10 states, then state counts will be done seperately for 10^3 = 1000 parents configurations. This makes MLE very fragile and unstable for learning Bayesian Network parameters. A way to mitigate MLE’s
overfitting is Bayesian Parameter Estimation.
Bayesian Parameter Estimation¶
The Bayesian Parameter Estimator starts with already existing prior CPDs, that express our beliefs about the variables before the data was observed. Those “priors” are then updated, using the state counts from the observed data. See [1], Section 17.3 for a general introduction to Bayesian estimators.
One can think of the priors as consisting in pseudo state counts, that are added to the actual counts before normalization. Unless one wants to encode specific beliefs about the distributions of the variables, one commonly chooses uniform priors, i.e. ones that deem all states equiprobable.
A very simple prior is the so-called K2 prior, which simply adds 1 to the count of every single state. A somewhat more sensible choice of prior is BDeu (Bayesian Dirichlet equivalent uniform prior). For BDeu we need to specify an equivalent sample size N and then the pseudo-counts are the equivalent of having observed N uniform samples of each variable (and each parent configuration). In pgmpy:
[6]:
from pgmpy.estimators import BayesianEstimator
est = BayesianEstimator(model, data)
print(est.estimate_cpd('tasty', prior_type='BDeu', equivalent_sample_size=10))
+------------+---------------------+-----+---------------------+
| fruit | fruit(apple) | ... | fruit(banana) |
+------------+---------------------+-----+---------------------+
| size | size(large) | ... | size(small) |
+------------+---------------------+-----+---------------------+
| tasty(no) | 0.34615384615384615 | ... | 0.6428571428571429 |
+------------+---------------------+-----+---------------------+
| tasty(yes) | 0.6538461538461539 | ... | 0.35714285714285715 |
+------------+---------------------+-----+---------------------+
The estimated values in the CPDs are now more conservative. In particular, the estimate for a small banana being not tasty is now around 0.64 rather than 1.0. Setting equivalent_sample_size to 10 means that for each parent configuration, we add the equivalent of 10 uniform samples (here: +5 small bananas that are tasty and +5 that aren’t).
BayesianEstimator, too, can be used via the fit()-method. Full example:
[7]:
import numpy as np
import pandas as pd
from pgmpy.models import BayesianModel
from pgmpy.estimators import BayesianEstimator
# generate data
data = pd.DataFrame(np.random.randint(low=0, high=2, size=(5000, 4)), columns=['A', 'B', 'C', 'D'])
model = BayesianModel([('A', 'B'), ('A', 'C'), ('D', 'C'), ('B', 'D')])
model.fit(data, estimator=BayesianEstimator, prior_type="BDeu") # default equivalent_sample_size=5
for cpd in model.get_cpds():
print(cpd)
/home/ankur/pgmpy_notebook/notebooks/pgmpy/models/BayesianModel.py:8: FutureWarning: BayesianModel has been renamed to BayesianNetwork. Please use BayesianNetwork class, BayesianModel will be removed in future.
warnings.warn(
+------+----------+
| A(0) | 0.511788 |
+------+----------+
| A(1) | 0.488212 |
+------+----------+
+------+---------------------+---------------------+
| A | A(0) | A(1) |
+------+---------------------+---------------------+
| B(0) | 0.49199687682998244 | 0.5002046245140168 |
+------+---------------------+---------------------+
| B(1) | 0.5080031231700176 | 0.49979537548598324 |
+------+---------------------+---------------------+
+------+--------------------+-----+---------------------+
| A | A(0) | ... | A(1) |
+------+--------------------+-----+---------------------+
| D | D(0) | ... | D(1) |
+------+--------------------+-----+---------------------+
| C(0) | 0.4882005899705015 | ... | 0.5085907138474126 |
+------+--------------------+-----+---------------------+
| C(1) | 0.5117994100294986 | ... | 0.49140928615258744 |
+------+--------------------+-----+---------------------+
+------+--------------------+---------------------+
| B | B(0) | B(1) |
+------+--------------------+---------------------+
| D(0) | 0.5120845921450151 | 0.48414271555996036 |
+------+--------------------+---------------------+
| D(1) | 0.4879154078549849 | 0.5158572844400396 |
+------+--------------------+---------------------+
Structure Learning¶
To learn model structure (a DAG) from a data set, there are two broad techniques:
score-based structure learning
constraint-based structure learning
The combination of both techniques allows further improvement: - hybrid structure learning
We briefly discuss all approaches and give examples.
This approach construes model selection as an optimization task. It has two building blocks:
A scoring function
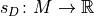 that maps models to a numerical score, based on how well they fit to a given data set
that maps models to a numerical score, based on how well they fit to a given data set 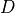 .
.A search strategy to traverse the search space of possible models
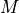 and select a model with optimal score.
and select a model with optimal score.
Scoring functions¶
Commonly used scores to measure the fit between model and data are Bayesian Dirichlet scores such as BDeu or K2 and the Bayesian Information Criterion (BIC, also called MDL). See [1], Section 18.3 for a detailed introduction on scores. As before, BDeu is dependent on an equivalent sample size.
[8]:
import pandas as pd
import numpy as np
from pgmpy.estimators import BDeuScore, K2Score, BicScore
from pgmpy.models import BayesianModel
# create random data sample with 3 variables, where Z is dependent on X, Y:
data = pd.DataFrame(np.random.randint(0, 4, size=(5000, 2)), columns=list('XY'))
data['Z'] = data['X'] + data['Y']
bdeu = BDeuScore(data, equivalent_sample_size=5)
k2 = K2Score(data)
bic = BicScore(data)
model1 = BayesianModel([('X', 'Z'), ('Y', 'Z')]) # X -> Z <- Y
model2 = BayesianModel([('X', 'Z'), ('X', 'Y')]) # Y <- X -> Z
print(bdeu.score(model1))
print(k2.score(model1))
print(bic.score(model1))
print(bdeu.score(model2))
print(k2.score(model2))
print(bic.score(model2))
-13938.353002020234
-14329.194269073454
-14294.390420213556
-20906.432489257266
-20933.26023936978
-20950.47339067585
/home/ankur/pgmpy_notebook/notebooks/pgmpy/models/BayesianModel.py:8: FutureWarning: BayesianModel has been renamed to BayesianNetwork. Please use BayesianNetwork class, BayesianModel will be removed in future.
warnings.warn(
While the scores vary slightly, we can see that the correct model1 has a much higher score than model2. Importantly, these scores decompose, i.e. they can be computed locally for each of the variables given their potential parents, independent of other parts of the network:
[9]:
print(bdeu.local_score('Z', parents=[]))
print(bdeu.local_score('Z', parents=['X']))
print(bdeu.local_score('Z', parents=['X', 'Y']))
-9282.88160824462
-6993.603560250576
-57.1217389219957
Search strategies¶
The search space of DAGs is super-exponential in the number of variables and the above scoring functions allow for local maxima. The first property makes exhaustive search intractable for all but very small networks, the second prohibits efficient local optimization algorithms to always find the optimal structure. Thus, identifiying the ideal structure is often not tractable. Despite these bad news, heuristic search strategies often yields good results.
If only few nodes are involved (read: less than 5), ExhaustiveSearch can be used to compute the score for every DAG and returns the best-scoring one:
[10]:
from pgmpy.estimators import ExhaustiveSearch
es = ExhaustiveSearch(data, scoring_method=bic)
best_model = es.estimate()
print(best_model.edges())
print("\nAll DAGs by score:")
for score, dag in reversed(es.all_scores()):
print(score, dag.edges())
[('X', 'Z'), ('Y', 'Z')]
All DAGs by score:
-14294.390420213556 [('X', 'Z'), ('Y', 'Z')]
-14330.086974085189 [('X', 'Z'), ('Y', 'Z'), ('Y', 'X')]
-14330.086974085189 [('X', 'Y'), ('X', 'Z'), ('Z', 'Y')]
-14330.08697408519 [('Y', 'X'), ('Z', 'X'), ('Z', 'Y')]
-14330.08697408519 [('Y', 'Z'), ('Y', 'X'), ('Z', 'X')]
-14330.08697408519 [('X', 'Y'), ('Z', 'X'), ('Z', 'Y')]
-14330.08697408519 [('X', 'Y'), ('X', 'Z'), ('Y', 'Z')]
-16586.926723773093 [('Y', 'X'), ('Z', 'X')]
-16587.66791728165 [('X', 'Y'), ('Z', 'Y')]
-18657.937087116316 [('Z', 'X'), ('Z', 'Y')]
-18657.937087116316 [('Y', 'Z'), ('Z', 'X')]
-18657.937087116316 [('X', 'Z'), ('Z', 'Y')]
-20914.776836804216 [('Z', 'X')]
-20914.776836804216 [('X', 'Z')]
-20915.518030312778 [('Z', 'Y')]
-20915.518030312778 [('Y', 'Z')]
-20950.47339067585 [('X', 'Z'), ('Y', 'X')]
-20950.47339067585 [('X', 'Y'), ('Z', 'X')]
-20950.47339067585 [('X', 'Y'), ('X', 'Z')]
-20951.21458418441 [('Y', 'X'), ('Z', 'Y')]
-20951.21458418441 [('Y', 'Z'), ('Y', 'X')]
-20951.21458418441 [('X', 'Y'), ('Y', 'Z')]
-23172.357780000675 []
-23208.05433387231 [('Y', 'X')]
-23208.05433387231 [('X', 'Y')]
Once more nodes are involved, one needs to switch to heuristic search. HillClimbSearch implements a greedy local search that starts from the DAG start (default: disconnected DAG) and proceeds by iteratively performing single-edge manipulations that maximally increase the score. The search terminates once a local maximum is found.
[11]:
from pgmpy.estimators import HillClimbSearch
# create some data with dependencies
data = pd.DataFrame(np.random.randint(0, 3, size=(2500, 8)), columns=list('ABCDEFGH'))
data['A'] += data['B'] + data['C']
data['H'] = data['G'] - data['A']
hc = HillClimbSearch(data)
best_model = hc.estimate(scoring_method=BicScore(data))
print(best_model.edges())
[('A', 'H'), ('B', 'A'), ('C', 'A'), ('G', 'H')]
The search correctly identifies e.g. that B and C do not influnce H directly, only through A and of course that D, E, F are independent.
To enforce a wider exploration of the search space, the search can be enhanced with a tabu list. The list keeps track of the last n modfications; those are then not allowed to be reversed, regardless of the score. Additionally a white_list or black_list can be supplied to restrict the search to a particular subset or to exclude certain edges. The parameter max_indegree allows to restrict the maximum number of parents for each node.
Constraint-based Structure Learning¶
A different, but quite straightforward approach to build a DAG from data is this:
Identify independencies in the data set using hypothesis tests
Construct DAG (pattern) according to identified independencies
(Conditional) Independence Tests¶
Independencies in the data can be identified using chi2 conditional independence tests. To this end, a conditional independence hypothesis test is performed to check if X is independent from Y given a set of variables Zs:
[12]:
from pgmpy.estimators import PC
from pgmpy.estimators.CITests import chi_square
data = pd.DataFrame(np.random.randint(0, 3, size=(2500, 8)), columns=list('ABCDEFGH'))
data['A'] += data['B'] + data['C']
data['H'] = data['G'] - data['A']
data['E'] *= data['F']
print(chi_square(X='B', Y='H', Z=[], data=data, significance_level=0.05)) # dependent
print(chi_square(X='B', Y='E', Z=[], data=data, significance_level=0.05)) # independent
print(chi_square(X='B', Y='H', Z=['A'], data=data, significance_level=0.05)) # independent
print(chi_square(X='A', Y='G', Z=[], data=data, significance_level=0.05)) # independent
print(chi_square(X='A', Y='G', Z=['H'], data=data, significance_level=0.05)) # dependent
False
True
True
True
False
The CITests.py module in pgmpy implements a few possible conditional independence tests.
DAG (pattern) construction¶
With a method for independence testing at hand, we can construct a DAG from the data set in three steps: 1. Construct an undirected skeleton - estimate_skeleton() 2. Orient compelled edges to obtain partially directed acyclid graph (PDAG; I-equivalence class of DAGs) - skeleton_to_pdag() 3. Extend DAG pattern to a DAG by conservatively orienting the remaining edges in some way - pdag_to_dag()
Step 1.&2. form the so-called PC algorithm, see [2], page 550. PDAGs are DirectedGraphs, that may contain both-way edges, to indicate that the orientation for the edge is not determined.
[13]:
est = PC(data)
skel, seperating_sets = est.build_skeleton(significance_level=0.01)
print("Undirected edges: ", skel.edges())
pdag = est.skeleton_to_pdag(skel, seperating_sets)
print("PDAG edges: ", pdag.edges())
model = pdag.to_dag()
print("DAG edges: ", model.edges())
Undirected edges: [('A', 'B'), ('A', 'C'), ('A', 'H'), ('E', 'F'), ('G', 'H')]
PDAG edges: [('A', 'H'), ('C', 'A'), ('G', 'H'), ('B', 'A'), ('E', 'F'), ('F', 'E')]
DAG edges: [('A', 'H'), ('C', 'A'), ('G', 'H'), ('B', 'A'), ('E', 'F')]
The estimate()-method provides a shorthand for the three steps above and directly returns a BayesianModel:
[14]:
print(est.estimate(significance_level=0.01).edges())
[('A', 'H'), ('C', 'A'), ('G', 'H'), ('B', 'A'), ('E', 'F')]
PC PDAG construction is only guaranteed to work under the assumption that the identified set of independencies is faithful, i.e. there exists a DAG that exactly corresponds to it. Spurious dependencies in the data set can cause the reported independencies to violate faithfulness. It can happen that the estimated PDAG does not have any faithful completions (i.e. edge orientations that do not introduce new v-structures). In that case a warning is issued.
Hybrid Structure Learning¶
The MMHC algorithm [3] combines the constraint-based and score-based method. It has two parts:
Learn undirected graph skeleton using the constraint-based construction procedure MMPC
Orient edges using score-based optimization (BDeu score + modified hill-climbing)
We can perform the two steps seperately, more or less as follows:
[15]:
from pgmpy.estimators import MmhcEstimator
from pgmpy.estimators import BDeuScore
data = pd.DataFrame(np.random.randint(0, 3, size=(2500, 8)), columns=list('ABCDEFGH'))
data['A'] += data['B'] + data['C']
data['H'] = data['G'] - data['A']
data['E'] *= data['F']
mmhc = MmhcEstimator(data)
skeleton = mmhc.mmpc()
print("Part 1) Skeleton: ", skeleton.edges())
# use hill climb search to orient the edges:
hc = HillClimbSearch(data)
model = hc.estimate(tabu_length=10, white_list=skeleton.to_directed().edges(), scoring_method=BDeuScore(data))
print("Part 2) Model: ", model.edges())
Part 1) Skeleton: [('A', 'B'), ('A', 'C'), ('A', 'H'), ('A', 'E'), ('A', 'G'), ('B', 'E'), ('C', 'G'), ('C', 'D'), ('D', 'F'), ('E', 'F'), ('E', 'H'), ('F', 'G'), ('G', 'H')]
Part 2) Model: [('A', 'H'), ('B', 'A'), ('C', 'A'), ('F', 'E'), ('G', 'H')]
MmhcEstimator.estimate() is a shorthand for both steps and directly estimates a BayesianModel.
Conclusion¶
This notebook aimed to give an overview of pgmpy’s estimators for learning Bayesian network structure and parameters. For more information about the individual functions see their docstring documentation. If you used pgmpy’s structure learning features to satisfactorily learn a non-trivial network from real data, feel free to drop us an eMail via the mailing list or just open a Github issue. We’d like to put your network in the examples-section!
References¶
[1] Koller & Friedman, Probabilistic Graphical Models - Principles and Techniques, 2009
[2] Neapolitan, Learning Bayesian Networks, 2003
[3] Tsamardinos et al., The max-min hill-climbing BN structure learning algorithm, 2005