Parameterizing with Continuous Variables¶
[1]:
from IPython.display import Image
Continuous Factors¶
Base Class for Continuous Factors
Joint Gaussian Distributions
Canonical Factors
Linear Gaussian CPD
In many situations, some variables are best modeled as taking values in some continuous space. Examples include variables such as position, velocity, temperature, and pressure. Clearly, we cannot use a table representation in this case.
Nothing in the formulation of a Bayesian network requires that we restrict attention to discrete variables. The only requirement is that the CPD, 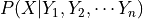 represent, for every assignment of values
represent, for every assignment of values 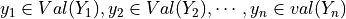 , a distribution over
, a distribution over 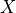 . In this case, might be continuous, in which case the CPD would need to represent distributions over a continuum of values; we might also have ’s parents
continuous, so that the CPD would also need to represent a continuum of different probability distributions. There exists implicit representations for CPDs of this type, allowing us to apply all the network machinery for the continuous case as well.
. In this case, might be continuous, in which case the CPD would need to represent distributions over a continuum of values; we might also have ’s parents
continuous, so that the CPD would also need to represent a continuum of different probability distributions. There exists implicit representations for CPDs of this type, allowing us to apply all the network machinery for the continuous case as well.
Base Class for Continuous Factors¶
This class will behave as a base class for the continuous factor representations. All the present and future factor classes will be derived from this base class. We need to specify the variable names and a pdf function to initialize this class.
[3]:
import numpy as np
from scipy.special import beta
# Two variable drichlet ditribution with alpha = (1,2)
def drichlet_pdf(x, y):
return (np.power(x, 1)*np.power(y, 2))/beta(x, y)
from pgmpy.factors.continuous import ContinuousFactor
drichlet_factor = ContinuousFactor(['x', 'y'], drichlet_pdf)
[4]:
drichlet_factor.scope(), drichlet_factor.assignment(5,6)
[4]:
(['x', 'y'], 226800.0)
This class supports methods like marginalize, reduce, product and divide just like what we have with discrete classes. One caveat is that when there are a number of variables involved, these methods prove to be inefficient and hence we resort to certain Gaussian or some other approximations which are discussed later.
[5]:
def custom_pdf(x, y, z):
return z*(np.power(x, 1)*np.power(y, 2))/beta(x, y)
custom_factor = ContinuousFactor(['x', 'y', 'z'], custom_pdf)
[6]:
custom_factor.scope(), custom_factor.assignment(1, 2, 3)
[6]:
(['x', 'y', 'z'], 24.0)
[7]:
custom_factor.reduce([('y', 2)])
custom_factor.scope(), custom_factor.assignment(1, 3)
[7]:
(['x', 'z'], 24.0)
[8]:
from scipy.stats import multivariate_normal
std_normal_pdf = lambda *x: multivariate_normal.pdf(x, [0, 0], [[1, 0], [0, 1]])
std_normal = ContinuousFactor(['x1', 'x2'], std_normal_pdf)
std_normal.scope(), std_normal.assignment([1, 1])
[8]:
(['x1', 'x2'], 0.058549831524319168)
[9]:
std_normal.marginalize(['x2'])
std_normal.scope(), std_normal.assignment(1)
[9]:
(['x1'], 0.24197072451914328)
[10]:
sn_pdf1 = lambda x: multivariate_normal.pdf([x], [0], [[1]])
sn_pdf2 = lambda x1,x2: multivariate_normal.pdf([x1, x2], [0, 0], [[1, 0], [0, 1]])
sn1 = ContinuousFactor(['x2'], sn_pdf1)
sn2 = ContinuousFactor(['x1', 'x2'], sn_pdf2)
sn3 = sn1 * sn2
sn4 = sn2 / sn1
sn3.assignment(0, 0), sn4.assignment(0, 0)
[10]:
(0.063493635934240983, 0.3989422804014327)
The ContinuousFactor class also has a method discretize that takes a pgmpy Discretizer class as input. It will output a list of discrete probability masses or a Factor or TabularCPD object depending upon the discretization method used. Although, we do not have inbuilt discretization algorithms for multivariate distributions for now, the users can always define their own Discretizer class by subclassing the pgmpy.BaseDiscretizer class.
Joint Gaussian Distributions¶
In its most common representation, a multivariate Gaussian distribution over 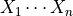 is characterized by an n-dimensional mean vector
is characterized by an n-dimensional mean vector 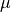 , and a symmetric
, and a symmetric 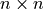 covariance matrix
covariance matrix 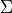 . The density function is most defined as -
. The density function is most defined as -
![p(x) = \dfrac{1}{(2\pi)^{n/2}| \Sigma |^{1/2}} \exp[-0.5*(x- \mu )^T \Sigma^{-1}(x- \mu)]](../_images/math/982dfc48a3c00e9aeea07cd521c5a5fccad81f0a.png)
The class pgmpy.JointGaussianDistribution provides its representation. This is derived from the class pgmpy.ContinuousFactor. We need to specify the variable names, a mean vector and a covariance matrix for its inialization. It will automatically comute the pdf function given these parameters.
[11]:
from pgmpy.factors.distributions import GaussianDistribution as JGD
dis = JGD(['x1', 'x2', 'x3'], np.array([[1], [-3], [4]]),
np.array([[4, 2, -2], [2, 5, -5], [-2, -5, 8]]))
dis.variables
[11]:
['x1', 'x2', 'x3']
[12]:
dis.mean
[12]:
array([[ 1.],
[-3.],
[ 4.]])
[13]:
dis.covariance
[13]:
array([[ 4., 2., -2.],
[ 2., 5., -5.],
[-2., -5., 8.]])
[14]:
dis.pdf([0,0,0])
[14]:
0.0014805631279234139
This class overrides the basic operation methods (marginalize, reduce, normalize, product and divide) as these operations here are more efficient than the ones in its parent class. Most of these operation involve a matrix inversion which is 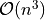 with repect to the number of variables.
with repect to the number of variables.
[15]:
dis1 = JGD(['x1', 'x2', 'x3'], np.array([[1], [-3], [4]]),
np.array([[4, 2, -2], [2, 5, -5], [-2, -5, 8]]))
dis2 = JGD(['x3', 'x4'], [1, 2], [[2, 3], [5, 6]])
dis3 = dis1 * dis2
dis3.variables
[15]:
['x1', 'x2', 'x3', 'x4']
[16]:
dis3.mean
[16]:
array([[ 1.6],
[-1.5],
[ 1.6],
[ 3.5]])
[17]:
dis3.covariance
[17]:
array([[ 3.6, 1. , -0.4, -0.6],
[ 1. , 2.5, -1. , -1.5],
[-0.4, -1. , 1.6, 2.4],
[-1. , -2.5, 4. , 4.5]])
The others methods can also be used in a similar fashion.
Canonical Factors¶
While the Joint Gaussian representation is useful for certain sampling algorithms, a closer look reveals that it can also not be used directly in the sum-product algorithms. Why? Because operations like product and reduce, as mentioned above involve matrix inversions at each step.
So, in order to compactly describe the intermediate factors in a Gaussian network without the costly matrix inversions at each step, a simple parametric representation is used known as the Canonical Factor. This representation is closed under the basic operations used in inference: factor product, factor division, factor reduction, and marginalization. Thus, we can define a set of simple data structures that allow the inference process to be performed. Moreover, the integration operation required by marginalization is always well defined, and it is guaranteed to produce a finite integral under certain conditions; when it is well defined, it has a simple analytical solution.
A canonical form 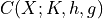 is defined as:
is defined as:
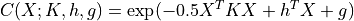
We can represent every Gaussian as a canonical form. Rewriting the joint Gaussian pdf we obtain,
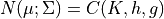 where:
where:
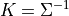
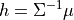
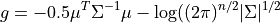
Similar to the JointGaussainDistribution class, the CanonicalFactor class is also derived from the ContinuousFactor class but with its own implementations of the methods required for the sum-product algorithms that are much more efficient than its parent class methods. Let us have a look at the API of a few methods in this class.
[18]:
from pgmpy.factors.continuous import CanonicalDistribution
phi1 = CanonicalDistribution(['x1', 'x2', 'x3'],
np.array([[1, -1, 0], [-1, 4, -2], [0, -2, 4]]),
np.array([[1], [4], [-1]]), -2)
phi2 = CanonicalDistribution(['x1', 'x2'], np.array([[3, -2], [-2, 4]]),
np.array([[5], [-1]]), 1)
phi3 = phi1 * phi2
phi3.variables
[18]:
['x1', 'x2', 'x3']
[19]:
phi3.h
[19]:
array([[ 6.],
[ 3.],
[-1.]])
[20]:
phi3.K
[20]:
array([[ 4., -3., 0.],
[-3., 8., -2.],
[ 0., -2., 4.]])
[21]:
phi3.g
[21]:
-1
This class also has a method, to_joint_gaussian to convert the canoncial representation back into the joint gaussian distribution.
[22]:
phi = CanonicalDistribution(['x1', 'x2'], np.array([[3, -2], [-2, 4]]),
np.array([[5], [-1]]), 1)
jgd = phi.to_joint_gaussian()
jgd.variables
[22]:
['x1', 'x2']
[23]:
jgd.covariance
[23]:
array([[ 0.5 , 0.25 ],
[ 0.25 , 0.375]])
[24]:
jgd.mean
[24]:
array([[ 2.25 ],
[ 0.875]])
Linear Gaussian CPD¶
A linear gaussian conditional probability distribution is defined on a continuous variable. All the parents of this variable are also continuous. The mean of this variable, is linearly dependent on the mean of its parent variables and the variance is independent.
For example,
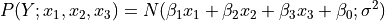
Let 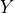 be a linear Gaussian of its parents $X_1, \cdots, X_k:
be a linear Gaussian of its parents $X_1, \cdots, X_k:
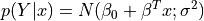
The distribution of is a normal distribution 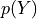 where:
where:
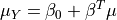
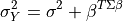
The joint distribution over 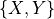 is a normal distribution where:
is a normal distribution where:
![Cov[X_i; Y] = {\sum_{j=1}^{k} \beta_j \Sigma_{i,j}}](../_images/math/46084dc187b8bdbde7f6b78280dc2350e173aad8.png)
Assume that 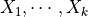 are jointly Gaussian with distribution
are jointly Gaussian with distribution 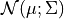 . Then: For its representation pgmpy has a class named LinearGaussianCPD in the module pgmpy.factors.continuous. To instantiate an object of this class, one needs to provide a variable name, the value of the
. Then: For its representation pgmpy has a class named LinearGaussianCPD in the module pgmpy.factors.continuous. To instantiate an object of this class, one needs to provide a variable name, the value of the 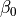 term, the variance, a list of the parent variable names and a list of the coefficient values of the linear equation (beta_vector), where the list of parent variable
names and beta_vector list is optional and defaults to None.
term, the variance, a list of the parent variable names and a list of the coefficient values of the linear equation (beta_vector), where the list of parent variable
names and beta_vector list is optional and defaults to None.
[25]:
# For P(Y| X1, X2, X3) = N(-2x1 + 3x2 + 7x3 + 0.2; 9.6)
from pgmpy.factors.continuous import LinearGaussianCPD
cpd = LinearGaussianCPD('Y', [0.2, -2, 3, 7], 9.6, ['X1', 'X2', 'X3'])
print(cpd)
P(Y | X1, X2, X3) = N(-2*X1 + 3*X2 + 7*X3 + 0.2; 9.6)
A Gaussian Bayesian is defined as a network all of whose variables are continuous, and where all of the CPDs are linear Gaussians. These networks are of particular interest as these are an alternate form of representaion of the Joint Gaussian distribution.
These networks are implemented as the LinearGaussianBayesianNetwork class in the module, pgmpy.models.continuous. This class is a subclass of the BayesianModel class in pgmpy.models and will inherit most of the methods from it. It will have a special method known as to_joint_gaussian that will return an equivalent JointGuassianDistribution object for the model.
[26]:
from pgmpy.models import LinearGaussianBayesianNetwork
model = LinearGaussianBayesianNetwork([('x1', 'x2'), ('x2', 'x3')])
cpd1 = LinearGaussianCPD('x1', [1], 4)
cpd2 = LinearGaussianCPD('x2', [-5, 0.5], 4, ['x1'])
cpd3 = LinearGaussianCPD('x3', [4, -1], 3, ['x2'])
# This is a hack due to a bug in pgmpy (LinearGaussianCPD
# doesn't have `variables` attribute but `add_cpds` function
# wants to check that...)
cpd1.variables = [*cpd1.evidence, cpd1.variable]
cpd2.variables = [*cpd2.evidence, cpd2.variable]
cpd3.variables = [*cpd3.evidence, cpd3.variable]
model.add_cpds(cpd1, cpd2, cpd3)
jgd = model.to_joint_gaussian()
jgd.variables
[26]:
['x1', 'x2', 'x3']
[27]:
jgd.mean
[27]:
array([[ 1. ],
[-4.5],
[ 8.5]])
[28]:
jgd.covariance
[28]:
array([[ 4., 2., -2.],
[ 2., 5., -5.],
[-2., -5., 8.]])